古典籍資料のOCRテキスト化実験(令和4年度~)
令和4年度以降、令和3年度OCR処理プログラム研究開発 及び令和4年度NDLOCR追加開発事業で得た知見を生かし、古典籍資料を対象としたOCR処理プログラム(以下、「NDL古典籍OCR」といいます。)の内製開発と、古典籍資料のテキスト化実験を実施しています。
令和5年8月8日にNDL古典籍OCR ver.2を公開しました。読み順整序機能が向上したほか、文字認識性能が改善しています。
令和6年2月7日にNDL古典籍OCR ver.3を公開しました。漢籍資料のレイアウト認識性能が向上しています。
※資料毎にばらつきがありますが、ver.2をver.1と文字認識性能で比較すると概ね約2%文字認識の正確性が改善しています。評価用に学習対象から除外した みんなで翻刻「翻刻!江戸の医療と養生」プロジェクト(外部サイト)の翻刻テキスト3,028画像分を正解としてver.2のテキスト化品質を評価すると、F値(後述)の中央値は0.92程度でした。ver.3は和古書資料についてはver.2とほぼ同様の性能を有していますが、漢籍資料についての性能が改善しています。
1. 古典籍資料のOCRテキスト化実験の意義
昨今のAI(機械学習)を用いたOCR(光学的文字認識)処理技術の進展により、画像データからテキストデータを作成し、本文検索サービスとして提供することが可能となってきました。
当館においても、デジタル化資料をOCR処理によってテキスト化し、デジタル化資料の本文検索サービスを提供しています。
しかし、国立国会図書館デジタルコレクションから提供している古典籍資料は、OCRテキスト化作業の対象外でした。
こうした資料の多くには、くずし字や異体字、変体仮名等が使われており、専門的な知識がないと判読自体が難しい資料が多く存在します。
利用者が必要とする古典籍資料をより簡単に発見できるようになることは、単に利便性の向上のみならず、パブリックドメインとなった資料の利活用促進の観点からも大きな意義があります。
そのため、まずは本文を自動的に読み取って文字列として検索できるようにし、求める資料にたどり着きやすくすることは重要です。
求める資料にたどり着きやすくすることで、新たな発見につながる可能性があります。また、くずし字になじみのない研究分野からのアプローチも可能となります。
2. 古典籍資料のOCRテキスト化の先行事例
古典籍資料を対象としたOCRテキスト化の先行事例としては、 人文学オープンデータ共同利用センターが開発している『みを』や、凸版印刷株式会社が開発している『ふみのは』といった くずし字OCRアプリケーションが存在しますが、 これらは、スマートフォンやタブレット端末の専用アプリケーションとして、利用者が撮影した個々の古典籍資料の判読のサポートやテキスト化を行える機能を備えたものです。
一方で、当館のような数百万画像規模の古典籍資料を所有する機関がOCRによるテキスト化を実施するためには、大量の画像に対して、自らの計算機サーバ上で高速なテキスト化処理を行えるOCR処理プログラムが必要となります。
3. 古典籍資料のOCRテキスト化実験の対象資料
国立国会図書館デジタルコレクションからインターネットで提供しているデジタル化済みの古典籍資料(江戸期以前の和古書、清代以前の漢籍等。著作権保護期間満了分約8万点、430万画像)です。
4. 古典籍資料のOCRテキスト化実験の概要
当館は、令和3年度OCR処理プログラム研究開発により、明治期以降の活字資料を対象としたOCR(NDLOCR)を開発した経験があります。 この研究開発の経験やこれまでNDLラボでの研究開発によって得た知見を応用することで、当館の次世代システム開発研究室で古典籍資料のOCRテキスト化実験を実施しました。
本実験は、これまで日本の研究機関や図書館等がデジタル人文学分野において構築しオープンデータとして公開してきた様々なデータセットを活用しています。
NDL古典籍OCRは、3つの機械学習モデルによって、OCRテキスト化に必要な機能を実現しています。 それぞれの機械学習モデルが学習するためのデータセットを準備し、データセットを利用した学習をそれぞれ行い、学習後の3モデルを組み合わせることで開発しました。
そして、開発したNDL古典籍OCRを利用して、当館が国立国会図書館デジタルコレクションから提供しているデジタル化済み古典籍資料のテキスト化を実施しました。
4.1. レイアウト認識モデル
資料画像中のどの領域にテキスト化するべき文字列が存在するかを自動で認識するモデルです。 機械学習モデルには、令和3年度OCR処理プログラム研究開発にて、活字資料の画像のレイアウト認識モデルを検討した際に、高い性能を発揮した、 MITライセンスのオープンソースであるCascade Mask RCNNを利用し、 学習のためのデータセットには、NDLラボから2019年に公開したNDL-DocLデータセットのうち古典籍資料から作成したデータセットを利用しています。 ver.2の開発にあたっては、これに加えて新規に作成したデータセット866画像分を追加しています。
ver.2のレイアウト認識モデルによって自動認識されたレイアウト(青枠)の例。

岡安定 著『救荒野菜圖説』,寛栗堂,渾沌舎,嘉永4 [1851]. 国立国会図書館デジタルコレクション(参照 2023-08-01)
ver.3ではver.2において性能が低下した漢籍資料についてレイアウト認識モデルの強化を行いました。
4.2. 文字列認識モデル
レイアウト認識モデルが認識した文字列領域を読み取って、テキストデータを作成するモデルです。 機械学習モデルには、マイクロソフト社がMITライセンスのオープンソースとして公開している、手書きの英文画像等を高精度にテキスト化できるTrOCRをベースに、 古典籍資料をテキスト化できるよう、読み取った特徴を文字に変換するdecoderと呼ばれる部分を差し替えたモデルを利用しています。
4.2.1. decoderの作成と学習
RoBERTa-smallを古典籍資料の翻刻テキスト用に改造して利用しています。 元のモデルは、京都大学の安岡孝一教授がCC-BY-4.0ライセンスで公開しているroberta-small-japanese-aozora-charをベースとし、 かつ、対象語彙を人文学オープンデータ共同利用センターが実施したKuzushiji Recognitionコンペティションにおいて精度の評価対象となったUnicodeリスト(4781文字種)のうち異体字の一部等を除外し、制御文字コード等を加えた4800種類に差し替えたモデルを利用しました。
decoderの学習には、次に挙げるいずれもオープンな古典籍の翻刻テキストデータ資源を利用しています。
- 『みんなで翻刻データ』 (CC-BY-SA-4.0ライセンス)
- 『吾妻鏡データベース(国文学研究資料館)』(CC-BY-SAライセンス)※ジャパンサーチAPI経由で取得
- 『絵入源氏物語データベース(国文学研究資料館)』(CC-BY-SAライセンス)※ジャパンサーチAPI経由で取得
- 『二十一代集データベース(国文学研究資料館)』(CC-BY-SAライセンス)※ジャパンサーチAPI経由で取得
- 『歴史物語データベース(国文学研究資料館)』(CC-BY-SAライセンス)※ジャパンサーチAPI経由で取得
次の図のようにdecoderに対して、文中の文字の約1割を欠落させた翻刻テキストデータを与え、欠落した文字を予測するよう訓練することで、前後の文字のつながりを学習させています。

4.2.2. モデル全体の学習
4.2.1で作成したdecoderによってTrOCRモデルを差し替えることで、画像を入力とし、テキストデータを出力とするモデルを作成しました。 今度はこのモデルに古典籍資料の読み方を学習させます。
文字列認識モデルの学習には、資料の画像と翻刻データについて1行単位で対応付けされたデータセットが必要ですが、このようなオープンな既存のデータセットは多くありません。 したがって、必要な形式に近い既存のデータセットを加工することで、目的に沿ったデータセットを可能な限り省力的に構築することが大きな課題となりました。
今回、このようなデータセットとして、CC-BY-SA-4.0ライセンスで公開されているみんなで翻刻のみんなで翻刻データに注目しました。
この翻刻データは紙面上での1行単位に対応づいて改行の入ったプレーンなテキストデータであり、翻刻作業の際に参照した資料画像上の位置座標の情報を有していませんが、 翻刻データと画像上の位置座標情報を正しく対応付けて構造化することができれば、文字列認識モデル用の高品質な学習データを大量に入手できると考えました。
そこで、次のとおり、1行単位の翻刻データから人工的に古典籍資料の1行単位の画像を作成し、これらを利用して仮の文字列認識モデルを学習させ、 この仮の文字列モデルを利用して、みんなで翻刻の翻刻成果物である翻刻データの構造化を行うことで文字列認識モデル用のデータセットを自動構築しました。
4.2.2.1. 人工的なデータセットの作成と仮の文字列認識モデルの学習
人文学オープンデータ共同利用センターから公開されている1文字単位の古典籍画像データセットである日本古典籍くずし字データセットを利用して、 4.2.1.に挙げたオープンなデータ資源から得られる翻刻データの各行と同じ内容を、1文字画像をつぎはぎすることで再現し、次の図のような1行単位の資料画像を人工的に作成しました。 この人工的なデータセットを356,187行分作成し、仮の文字列認識モデルの学習を行いました。

4.2.2.2. みんなで翻刻のテキストデータ構造化と学習
4.1.で作成したレイアウト認識モデルを利用して、みんなで翻刻の翻刻対象画像から読むべき文字列の含まれる領域を認識し、認識した位置の文字列領域に対して4.2.2.1.の仮の文字列認識モデルでテキスト化を行いました。
これにより、「(1)OCRによって読み取られた誤りを含むかもしれないテキストデータ」と「(2)(1)を読み取った翻刻元画像上の位置座標情報」の2つの情報が得られます。
次に、(1)のテキストデータに最も近い文字列が含まれた翻刻データの行を当該資料画像の翻刻テキストデータから探し、両者が十分に近い場合に対応付けを行いました。
これにより、みんなで翻刻の翻刻データと(2)の翻刻元画像上の位置座標情報について部分的な対応付けが行えました。
当然に、人工的に作成したデータセットの画像と実際の古典籍資料の画像には違いがあるため、仮の文字列認識モデルではみんなで翻刻の翻刻データの一部分にしか対応付けを行うことができません。
そこで、対応付けしたデータセットを利用して文字列認識モデルの再学習を行うことを繰り返しました。
再学習を繰り返すことで文字列認識モデルの性能が向上するため、対応付けの歩留まりも向上し、2回目の再学習時点で約6.6万行(120万文字相当)、 みんなで翻刻バージョン2のデータを対象に加えた3回目時点で約35万行(約530万文字相当)の対応付けを行うことができました。
みんなで翻刻のテキストデータと画像を対応付けて構造化した例
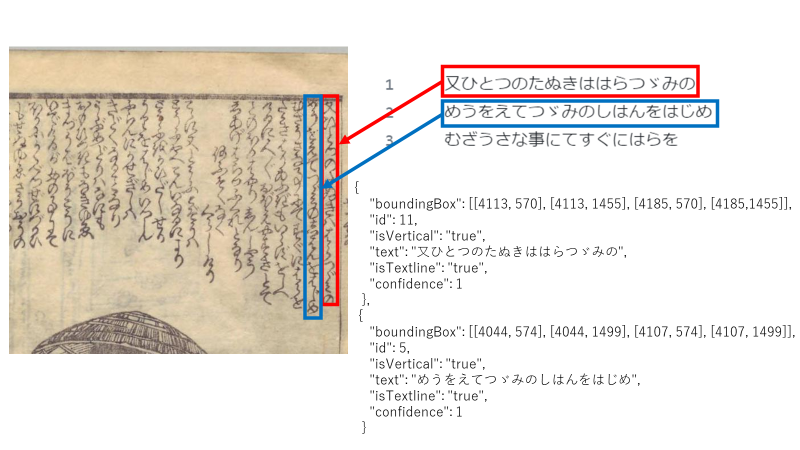
晋米齋玉粒 作 ほか『化物世帯氣質』,春松軒西宮新六,文政3 [1820]. 国立国会図書館デジタルコレクション(参照 2023-08-01)
ver.1は3回目の対応付けを行ったデータセットで学習した文字列認識モデルを利用して学習しています。
ver.2及びver.3では、更に多くの対応付けを進め、地震資料及び性能評価対象を除いた資料画像から作成した約45万行分のデータセットを得て、TrOCRの学習を行いました。
ver.2及びver.3の学習において地震資料を除いた趣旨は、ver.1の開発時に地震資料を多く含んだデータセットによってTrOCRの学習を進めたことで、地震資料に多く含まれる表現に引っ張られた文字の認識誤りが多く報告された反省を踏まえたものです。
4.3. 読み順整序モデル
ver.1では、読み順整序モデルには、当館が独自に開発した、レイアウト位置座標を用いてNDLOCRに読み順整序機能を追加するlightGBMモデルを利用し、 学習のためのデータセットには、4.2.2.2.で作成した2回目時点のデータセットと、みんなで翻刻の翻刻テキストデータが本来保持している読み順序を対応付けたデータセットを利用しました。
ver.2及びver.3では、令和4年度NDLOCR追加開発事業の成果を応用して、手法を差し替えることで読み順整序機能の性能を向上させました。
4.4.テキスト化の実施
ver.1では、作業は1並列あたりGPUを2基用いて3並列で実施し、2022年12月までの間に、約8万点の古典籍資料について、位置座標付きOCRテキストデータを作成しました。
令和6年2月には、ver.3を用いて、約8万点の古典籍資料について位置座標付きOCRテキストデータを再作成しました。
5. 性能測定結果
5.1. 評価方法
認識性能は、5文字以上の文字を含む画像ごとに文字単位についてF値($F_{measure}$)を計算することで評価しました。
F値の定義は次のとおりとしています。
としたとき
F値は0から1の範囲を取り、1に近づくほど高い認識性能を表します。
5.2. 文字認識性能(実績値)
『みんなで翻刻データ』 のうち、NDL古典籍OCRの機械学習モデルの学習データセット作成作業以降に公開された翻刻データから、 37資料(702画像)について、NDL古典籍OCRによる資料画像のテキスト化を行い、翻刻データを正解情報としてF値の中央値を計算しました。
また、ver.2及びver.3に関してはより多くの資料に対する性能評価結果を示すため、「翻刻!江戸の医療と養生プロジェクト(https://honkoku.org/app/#/projects/iryotoyojo/info )」に含まれる画像について学習データセットから除外し、74資料(3,028画像)に対する評価を別途行いました。
各資料に対する文字認識性能については文字認識性能評価結果(xlsxファイル 20KB)をご覧ください。
6. 成果物の公開
古典籍資料のOCRテキスト化実験の成果物は、次の形で提供しています。
① 次世代デジタルライブラリー
NDLラボの実験サービスである次世代デジタルライブラリーにおいて、全文テキスト検索機能及び全文テキストダウンロード機能を提供しています。
令和6年2月現在、ダウンロード可能なテキストはver.3で作成したものです。
古典籍資料のOCRテキスト化実験において作成したOCR全文テキストデータは全て著作権保護期間満了資料から作成していますので、自由な二次利用が可能です。
② ソースコード及び実験の過程で作成した機械学習データセット
(1) ソースコード(リリースノート)
公開日:令和6年2月7日
改修内容の概要:ver.2において性能が低下した漢籍資料の認識性能改善
公開日:令和5年8月8日
改修内容の概要:レイアウト認識モデル及び読み順整序モデルの変更。レイアウト認識モデル及び文字列推定モデルの再学習による特に和古書資料の認識性能改善
公開日:令和5年1月24日
ver.1及びver.2については、NDL古典籍OCRのGitHubリポジトリからブランチを分けて提供を継続します。
(2)機械学習データセット
OCR学習用データセット(みんなで翻刻)(GitHubリポジトリ):https://github.com/ndl-lab/ndl-minhon-ocrdataset
令和6年2月現在、ver.1の学習に利用したデータセット(ndl-minhon-ocrdataset.zip)に加えて、ver.2及びver.3の学習に利用したデータセット(ndl-minhon-ocrdataset_20240207.zip)を公開しています。