Experimental OCR conversion of rare books and old materials (since 2022)
We have been developing an in-house OCR processing program for pre-modern materials (NDLkotenOCR) and conducting experiments in converting those materials to text data since FY2022, utilizing the knowledge gained through the Development of Japanese OCR software project (FY2021) and Additional development of Japanese OCR software project (FY2022) (in Japanese).
The source code for NDLkotenOCR ver. 2 was released on August 8, 2023. The reading order detection functionality and the character recognition performance have been improved※.
※Although they vary depending on the document, a comparison of character recognition performance shows that ver. 2 is generally about 2% better than ver. 1. When we evaluated the quality of ver. 2 using the text data of 3,028 images from “Minna de Honkoku (external site)”, which were excluded from the training data for evaluation, as the ground truth, the median F-score (described below) was about 0.92.
1. Significance of the experiment
Recent advances in OCR (optical character recognition) technology based on AI (machine learning) have made it possible to create text data from images and use them to provide full-text search services. In OCR-related projects in FY2021, we converted almost all of the digitized materials provided by the NDL into text data through OCR processing for the realization of a text search service.
Pre-modern materials provided in the NDL Digital Collections were not targeted in the OCR text conversion of digitized materials project in FY2021. Because many of those documents use characters and variants that are no longer in use today, they are often difficult to decipher without some expertise. Making it easier for users to find such old materials they need will not only improve usability but will also be of great significance in terms of promoting the utilization of documents that have entered the public domain. Therefore, it is important to first make it easier to find materials by making it possible to search for text strings automatically generated from images of digitized materials. Facilitating access to materials in this way opens up the possibility of new discoveries. At the same time, it also enables research fields without expertise in older scripts to approach pre-modern materials.
2. Previous related projects
Previous efforts in OCR text conversion of pre-modern materials include applications such as miwo developed by the Center for Open Data in the Humanities (CODH) and Fuminoha developed by Toppan Printing Co. However, these are applications for smartphones and tablet devices that provide decipherment support and text conversion for pre-modern materials photographed by users.
On the other hand, for an institution such as the NDL, which holds millions of images of pre-modern materials, in order to convert them into text data using OCR, it is indispensable to have an OCR processing program that can perform high-speed text conversion on a computer server for a huge number of images.
3. Target materials of the experiment
The experiment targets approximately 80,000 items and 4.3 million images of digitized rare books and old materials (mainly Japanese classical books from before the Edo period and Chinese books from before the Qing dynasty) that are available on the internet in the NDL Digital Collections, for which the copyright protection period has expired.
4. Overview of the experiment
The NDL has experience in developing an OCR(NDLOCR) program for printed materials from the Meiji period onward through the Development of Japanese OCR software project (FY2021). By applying the knowledge gained through this project and past R&D activities at the NDL Lab, we conducted an OCR text conversion experiment on pre-modern materials.
This experiment utilizes various open datasets that have been created by Japanese research institutions or libraries in the field of digital humanities. NDLkotenOCR achieved the functionality required for OCR text conversion through three machine learning models as shown below. We developed it by preparing datasets to train those models, training them using the datasets, and then combining the three trained models.
We then used NDLkotenOCR to perform text conversion of the digitized old materials made available by the NDL in the NDL Digital Collections.
4.1. Layout recognition model
The model automatically detects areas containing text strings to be converted within an image. As the machine learning model, we adopted the MIT-licensed open source Cascade Mask R-CNN, which demonstrated high performance when we examined layout recognition models for images of printed materials in the Development of Japanese OCR software project (FY2021). As the dataset for training, we used the dataset created from pre-modern materials in the NDL-DocL datasets released by the NDL Lab in 2019. For the development of ver. 2, in addition to these, a newly created dataset of 866 images was added.
An example of automatic recognition by the ver. 2 layout recognition model (blue boxes):

Title: 救荒野菜圖説, Creator: 岡安定, Publisher: 寛栗堂 / 渾沌舎, Publication Date: 嘉永4 [1851].
Link to the document (NDL Digital Collections)
Link to the document (Next Digital Library)
4.2. Text recognition model
This model creates text data from areas of text strings recognized by the layout recognition model. The machine learning model is based on Microsoft's MIT-licensed open source TrOCR, which can convert handwritten English images into text with high accuracy, while the decoder, which converts the captured features into text data, has been replaced with one that could treat pre-modern documents.
4.2.1. Building and training of
As the decoder model, RoBERTa-small was adopted and customized for transcribed texts from pre-modern documents. Its original model is based on roberta-small-japanese-aozora-char developed and made available under the CC-BY-4.0 license by Prof. Koichi Yasuoka at Kyoto University. The target vocabulary consists of 4,800 characters, which is based on the Unicode list (4,781 character types) that was the target of accuracy evaluation in the Kuzushiji Recognition Competition conducted by CODH, but excludes some variants and adds some control characters. For training the decoder, we used the following open pre-modern text data resources:
For training the decoder, we used the following open pre-modern text data resources:
- Minna de Honkoku Data (CC-BY-SA-4.0)
- Azuma Kagami Database (National Institute of Japanese Literature (NIJL)) (CC-BY-SA)※
- E-iri Genji Monogatari Database (NIJL)』(CC-BY-SA)※
- Nijūichidaishū Database (NIJL) (CC-BY-SA)※
- Rekishi Monogatari Database (NIJL)(CC-BY-SA)※
※Obtained through Japan Search API. As shown in the following figure, we removed about 10% of characters from the text data and trained the decoder to predict the missing characters.

4.2.2. Training of the whole model
By replacing the decoder in the TrOCR model with the one created in 4.2.1, we successfully created a model that takes images as input and provides text data as output. Next, it was necessary to have this model learn how to read pre-modern materials. To train the text recognition model, datasets with line-by-line correspondence between image and text data were required, but there are not many such datasets openly available. Therefore, it was necessary to build a dataset that met our objectives in the most labor-saving way possible by modifying an existing dataset that was close to the format we needed.
As such a dataset, we adopted Minna de Honkoku Data, which is available under the CC-BY-SA-4.0 license. This transcribed text data is plain text data with line breaks at the same line level as the original documents. Although it does not have the positional coordinate information on the image that were referenced during the transcription process, we thought that if the transcribed text data and the positional coordinate information on the image were correctly mapped and properly structured, a large amount of high-quality training data for the text recognition model could be generated.
Therefore, we automatically produced a dataset for a character text recognition model through the following steps: artificially creating line-by-line images of pre-modern materials from line-by-line transcribed text data; using these images to train a provisional text recognition model; then structuring the transcribed text data, which is a product of Minna de Honkoku, by using this provisional model.
4.2.2.1. Creation of an artificial dataset and training of the provisional text recognition model
By using the Kuzushiji Dataset (a character-by-character image dataset) provided by the CODH, we artificially reproduced images of the same content as each line of the transcribed text data, obtained from open data resources listed in Section 4.2.1, by aligning those single character images as shown below. We created an artificial dataset of 356,187 lines and trained the provisional text recognition model.

4.2.2.2. Structuring and training text data of Minna de Honkoku
First, the layout recognition model developed in 4.1. was used to recognize regions containing the text strings to be read from images of Minna de Honkoku. Then, we performed text conversion using the provisional text recognition model mentioned in 4.2.2.1. for the regions containing recognized text strings.
By doing so, two types of information were obtained: (a) text data generated by OCR that may contain errors; and (b) positional coordinate information on the original images of (a).
Next, we searched the line of the text strings of transcribed text data on the Minna de Honkoku most similar to the text data in (a), and mapped them if the two were sufficiently similar.
Thus, a partial mapping was completed for the transcribed data of Minna de Honkoku and the positional coordinate information on the original images of (b).
Because there are obviously differences between the images in the artificially created dataset and the original images of the pre-modern materials, the provisional text recognition model can only partially map to the transcribed data of Minna de Honkoku.
We therefore iteratively trained the text recognition model using the successfully mapped dataset.
The performance of the text recognition model improved with repeated training. Mapping efficiency was also improved, with approximately 66,000 lines (1.2 million characters) completed at the end of the second training session, and approximately 350,000 lines (5.3 million characters) completed at the end of the third training session where data from Minna de Honkoku ver. 2 was added to the target.
Example of mapping and structuring text data from Minna de Honkoku and images:
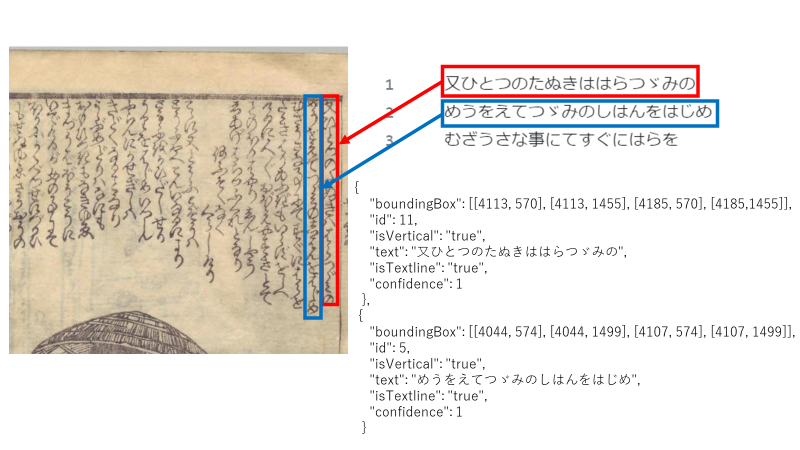
Title: 化物世帯氣質, Creator: 晋米齋玉粒 作 [et al.], Publisher: 春松軒西宮新六, Publication Date: 文政3 [1820].
Link to the document (NDL Digital Collections)
We trained NDLkotenOCR ver. 1 using the text recognition model trained on the dataset created by the three mapping sessions.
For ver. 2, TrOCR was trained using a dataset of approximately 450,000 lines of data created from images that have undergone further mapping and excluded seismic-related documents and materials subject to performance evaluation.
The reason why we excluded seismic data from the ver. 2 training is that during the development of ver. 1, we trained TrOCR on a dataset containing many earthquake-related materials, which resulted in frequent misrecognition of characters influenced by the expressions contained in such materials.
4.3. Reading order adjustment model
For OCR ver. 1, we adopted the lightGBM model, which adds a reading order adjustment function to NDLOCR using layout position coordinates, as its reading order adjustment model. As for the training dataset, we created a dataset that mapped the dataset after two rounds of training as described in 4.2.2. to the reading order originally retained by Minna de Honkoku text data, and used it.
For ver. 2, we improved the performance of the reading order adjustment function by applying the results of the FY2022 NDLOCR Additional Development Project (in Japanese) and replacing the method.
4.4. Conversion to text data
Text conversion was performed using OCR ver. 1, with 3 pairs of GPUs in parallel. By December 2022, text data with positional coordinates was created for approximately 80,000 pre-modern materials.
We plan to use the OCR ver. 2 to re-convert to text data for all of the same documents.
5. Achieved performance
5.1. Evaluation method
The recognition performance was evaluated by calculating an F-score($F_{measure}$)based on character units for each image containing 5 or more characters.
The F-score is defined as follows:
The F value ranges from 0 to 1, the closer to 1 the higher the recognition performance.
5.2. Recognition performance for characters (actual results)
From Minna de Honkoku Data, we selected 37 documents (702 images) that have been made public after the creation of the training dataset for NDLkotenOCR and converted the images into text using NDLkotenOCR. We then calculated the median of the F values using the transcribed text as ground truth.
As for ver. 2, in order to obtain performance evaluation results for a larger variety of materials, the images from the “翻刻!江戸の医療と養生プロジェクト” were excluded from the training dataset, and the evaluation for 74 materials (3,028 images) was conducted separately using the excluded images.
For the character recognition performance for each document, see Results of Character Recognition Performance Evaluation (xlsx file 20KB).
6. Availability of products
The products of the project are currently available as follows:
(1) Next Digital Library
Full-text search and download functions are available in Next Digital Library, an experimental service of NDL Lab.
As of August 2023, you can download the text data created by the OCR ver. 1.
Since all OCR full-text data in this project has been created from public domain materials, they are freely available for secondary use.
(2) Source codes and dataset
i. Source codes
N.B. The OCR ver. 1 is available in a branch of the ver. 2 repository.
ii. Dataset for machine-learning
OCR training dataset (Minna de Honkoku) (GitHub): https://github.com/ndl-lab/ndl-minhon-ocrdataset
As of August 2023, the available dataset is the one used for training the OCR ver.