NDL古典籍OCR-Liteの使い方
NDLラボでは、マウス操作だけで簡単に利用できるOCRソフトウェア「NDL古典籍OCR-Lite」を開発・公開しています。
このソフトウェアを利用することで、どなたでも簡易に古典籍資料(江戸期以前の和古書、清代以前の漢籍等)の画像を文字起こし(テキスト化)することができます(機械的な判断結果のため、誤りを含みます。)。
このページではWindowsユーザを対象に、簡単な使い方をご紹介します。
なお、Macユーザに向けての使い方については、当館非常勤調査員でもある東京大学史料編纂所の中村覚先生の記事「NDL古典籍OCR-Lite(ndlkotenocr-lite)をMac OSで使用する(https://zenn.dev/nakamura196/articles/c62a465537ff20 )」が参考になります。
(1) OCRのダウンロード
次が、ダウンロードサイトのURLです、リンクをたどってブラウザで表示してください。
https://github.com/ndl-lab/ndlkotenocr-lite/releases
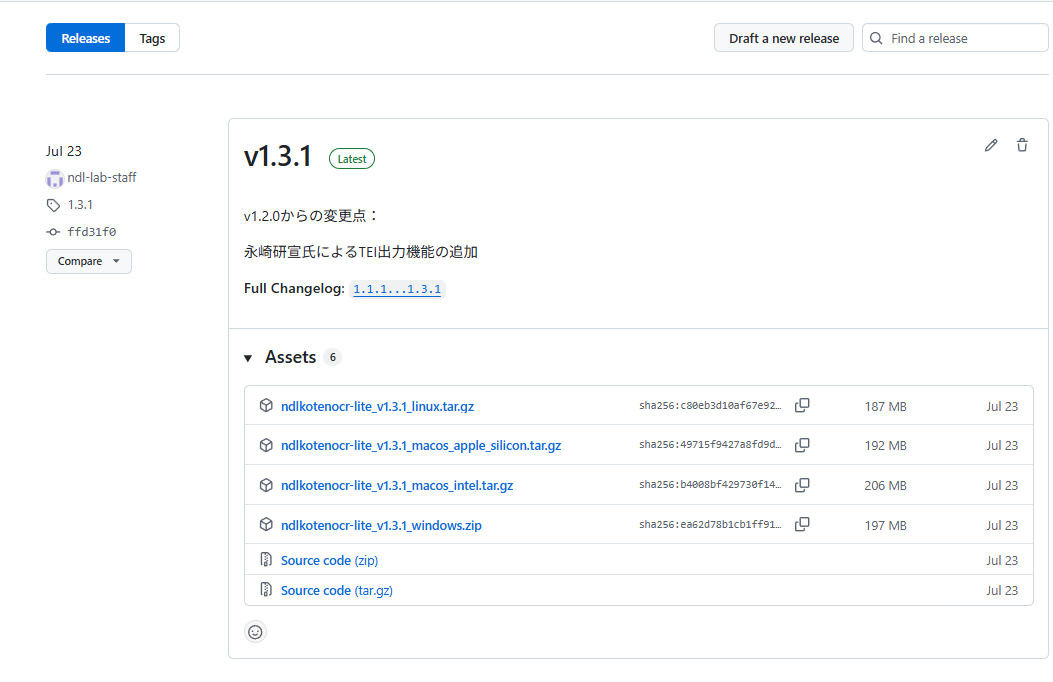
上のような画面が表示されます(バージョン番号「v1.3.1」は更新されている可能性があります。)。
ここでは、OSごとにダウンロードファイルを用意しています。利用したいOSのファイル(ファイル名に「Windows」を含むzipファイル。)のリンクを選択します(リンクをクリックすると、ダウンロードが始まります。)。ファイルは200MB弱ありますので、少々時間がかかります。
(2) ダウンロードファイルの展開
ダウンロードしたファイルは、exeファイル等をまとめたzip圧縮ファイルになっています。これを完全に展開します。
ファイルを右クリックして表示されるメニューから「すべてを展開…」を選ぶか、別途ソフトウェアを使用して、フォルダの中身を完全に展開します(zipファイルをダブルクリックしただけでは、圧縮ファイルの内容が表示されているだけの場合があります。)。
この時に、配置するフォルダの名称は半角の英数または記号とし、日本語等の全角文字を使わないようにしてください(日本語等の全角文字が含まれると起動しないことがあります)。
(3) OCRの起動
ダウンロードファイルの展開後に現れる「ndlkotenocr_lite.exe」ファイル(「古」のアイコン)をダブルクリックしてOCRを起動します。この時、セキュリティの警告画面が表示されることがありますが、そのまま進めてください。
また、初回のみ、画面枠が表示されてから画面の内容が描画されるまで少々時間がかかります。
次のような画面が表示されればOKです。

(4)資料のテキスト化(1枚の画像をテキスト化する)
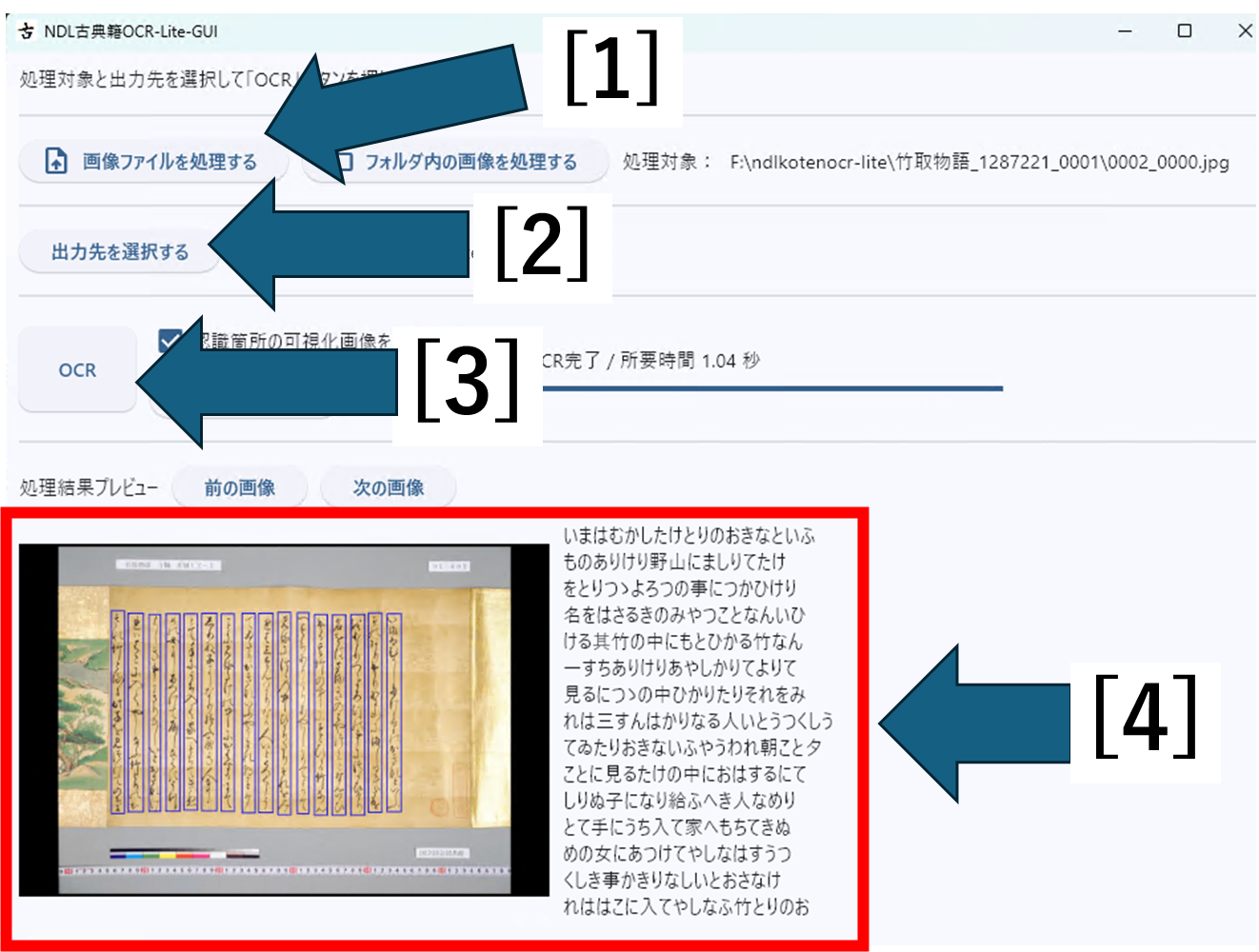
[1] 「画像ファイルを処理する」ボタンを押して、表示されるファイル選択画面から、テキスト化したい画像ファイルを選びます。
[2] 「出力先を選択する」ボタンを押して、表示されるフォルダ選択画面から、テキスト化結果の出力先フォルダを選択します。
[3] 「OCR」ボタンを押します。これによりテキスト化が始まります。
[4] テキスト化が終了すると、下部に結果が表示されます。
[5] [2]で指定した出力先のフォルダを開くと、テキストデータ等が出力されています。これをマウス操作で選択してコピー&ペーストすることもできます。

(5)資料のテキスト化(フォルダの中の画像をまとめてテキスト化する)
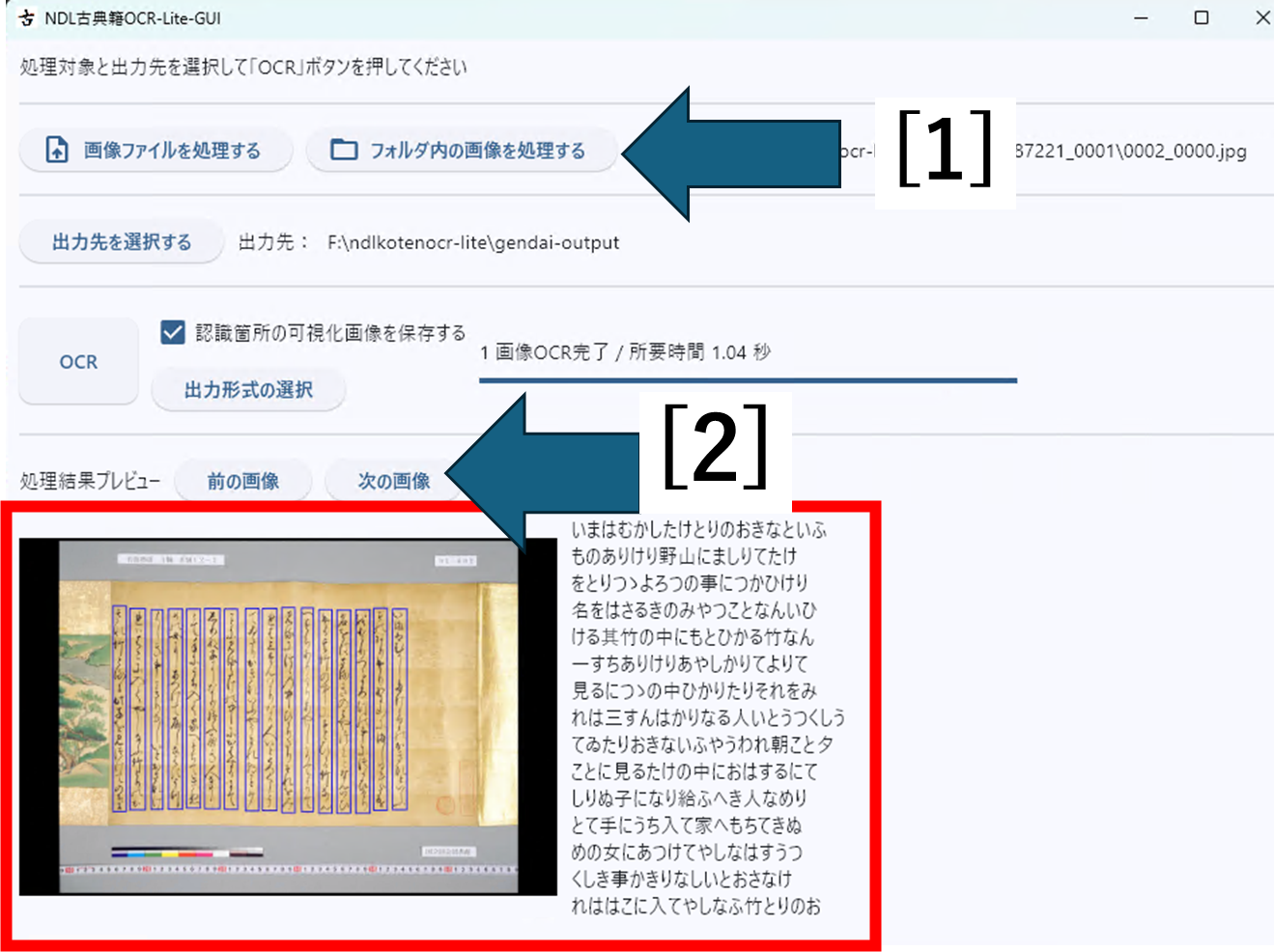
[1] 「フォルダ内の画像を処理する」ボタンを押して、表示されるフォルダ選択画面からテキスト化したい画像の含まれるフォルダを選びます。続いて、上の(4)と同様にテキストの出力先を選択して「OCR」ボタンを押します。
[2] フォルダの中の複数の画像をまとめてテキスト化したときは、「前の画像」「次の画像」でOCR結果のテキストデータをコマ送りできます。
(6)出力ファイルの形式選択
「出力形式の選択」ボタンを押すと、出力ファイルの形式を選択できます。ここで選択した形式が、「出力先を選択する」で設定したフォルダに出力されます。

出力ファイルのそれぞれの形式の説明は次のとおりです。
- TXT形式:構造情報を持たない文字列情報のみのテキストデータです。
- JSON形式:1行の文字列ごとに、文字列を囲む座標情報とその中の文字列のテキストデータがjson形式で格納されています。
- XML形式:レイアウト情報、座標情報、及び内部の文字列のテキストデータ等がxml形式で格納されています。
- TEI形式:TEI(Text Encoding Initiative)に準拠した形式のテキストデータです。
- 透明テキスト付PDF形式:PDFにテキストデータを透明テキストとして埋め込んだ形式です。内部の検索やコピー&ペーストができます。